文章目录
- Speech2Action: 基于跨模态监督的动作识别
- 摘要
- 1. 引言
- 2. 相关工作
- 将剧本与电影对齐
- 动作识别的监督
- 3. Speech2Action模型
- 3.1 IMSDb 数据集
- 剧本解析
- 动词挖掘舞台指令
- 基于BERT的语音分类器
- 实现细节
- 结果
- 4. 动作识别视频挖掘
- 4.1 未标注的数据
- 4.2 获取弱标签
- 4.2.1 使用Speech2Action
- 4.2.
- 4.2.3 Speech2Action的手动评估
- 5. 动作分类
- 5.1 评估协议
- 5.2 数据集和实验细节
- 实现细节
- 训练的损失函数
- 5.3 结果
- AVA-scratch
- AVA-finetuned
- 挖掘技术
- 抽象动作
- 6. 结论
Speech2Action: 基于跨模态监督的动作识别
摘要
仅通过对话猜测人类动作是否可能?在这项工作中,我们研究了电影中口语和动作之间的联系。我们注意到电影剧本不仅描述了动作,还包含了角色的对话,因此可以在无需额外监督的情况下学习这种关联。我们训练了一个基于BERT的Speech2Action分类器,用超过一千部电影剧本来预测从转录的语音片段中提取的动作标签。然后我们将该模型应用于一个大型未标注的电影语音片段集(188M语音片段,来自288K电影)。利用该模型的预测结果,我们为超过80万视频片段获得了弱动作标签。通过这些视频片段的训练,我们在标准动作识别基准测试中展示了优越的动作识别性能,而无需使用单个手动标注的动作示例。
1. 引言
在电影中,仅通过听对话,你经常可以大致了解人类活动。例如,句子“看那边的那个点”,表示某人正在指向某物。同样,句子“你好,谢谢你的来电”通常表示某人在接电话。这样的话是否能成为学习良好动作识别模型的有价值信息源?获得大规模人类标注的视频数据集来训练视觉动作识别模型是一个非常具有挑战性的任务。尽管现在已有一些大型数据集(如Kinetics或Moments in Time),这些数据集由单个短片(例如10秒)组成,但这些数据集的构建需要巨大的人工成本和努力。此外,许多此类数据集存在严重的不平衡分布问题——即很难为罕见或不常见的动作获得手动标签。最近,一些工作创造性地确定了某些视频领域,例如讲解视频和生活视频博客,这些视频在YouTube上大量存在,并且通常包含旨在解释屏幕上视觉内容的解说。在这些视频领域,动作和视频解说之间存在直接联系——尽管这种联系以及它提供的视觉监督可能相当弱且“嘈杂”,因为解说可能涉及先前或即将发生的视觉事件,或者完全与正在讨论的内容无关。在本文中,我们探索了电影和电视节目中语音和动作之间的互补联系(不限于讲解视频和生活视频博客)。我们问:仅给定一句话,能否预测动作是否发生,如果能,是什么动作?虽然有时语音与动作相关——例如“举起你的杯子……”,但在更一般的电影和电视节目领域,语音更可能完全与动作无关——例如“你今天过得怎么样?”。因此,在这项工作中,我们明确地学习了语音何时具有辨别性。虽然我们从语音-动作关联中获得的监督仍然嘈杂,但我们展示了在大规模数据上,它可以提供足够的弱监督来训练视觉分类器(见图1)。
幸运的是,我们有大量的文学内容可以用来学习语音和动作之间的关联。可以找到数百部电影和电视节目的剧本,这些剧本包含了丰富的人物身份、动作及其相互作用的描述以及对话。早期的工作曾尝试将这些剧本与视频本身对齐,并将其用作弱监督的来源。然而,由于视频中场景元素与剧本中的文本描述缺乏明确的对应关系,这种方法存在挑战。此外,这种对齐方法在规模上也受限于可用的对齐电影剧本的数量。因此,以前的工作限于少数几部电影或一个电视季。在本文中,我们从未对齐的电影剧本中学习。我们首先仅从书面材料中学习语音和动作之间的关联,然后用这些知识训练一个Speech2Action分类器。然后将该分类器应用于未标注、未对齐的视频集合中的语音,获取与语音信心预测的动作相对应的视觉样本(图1)。通过这种方式,关联可以为我们提供一个无限有效的弱训练数据源,因为音频在电影中是免费的。
具体来说,我们做出了以下四点贡献:
- 我们从文学剧本中训练了一个Speech2Action模型,并展示了仅通过转录的语音即可预测某些动作而无需任何手动标注。
- 我们将Speech2Action模型应用于一个大型未标注的视频集合,仅从语音中获取视频片段的弱标签。
- 我们展示了用这些弱标签训练的动作分类器在标准基准测试中的动作分类性能优于其他弱监督/领域迁移方法。
- 最后也是更有趣的是,我们在中尾类中评估了仅用这些弱标签训练的动作分类器,在零样本和少样本设置中展示了显著提升,而无需使用单个手动标注的示例。
2. 相关工作
将剧本与电影对齐
一些工作探讨了利用剧本来学习和自动注释电视连续剧中的角色身份。学习人类动作的研究也曾尝试过。然而,所有这些工作都依赖于将这些剧本与实际视频对齐,通常使用语音(如字幕)来提供对应关系。然而,正如所指出的,通过这种方式获得动作的监督具有挑战性,因为视频中的场景元素与剧本中的文本描述之间缺乏明确的对应关系。除从字幕对应关系推断出的时间定位不准确外,这种方法的一个主要限制是这种方法不能扩展到所有电影和电视节目,因为带有舞台指令的剧本数量远远不够。因此,以前的工作被限制在小规模的应用中,不超过几十部电影或一个电视季。类似的论点也可以适用于将书籍与电影对齐的工作。相比之下,我们提出了一种方法,可以利用数量适中的剧本中的丰富信息,并且可以应用于无限数量的已编辑视频素材,而无需对齐或手动注释。
动作识别的监督
众所周知,大规模监督视频数据集对动作识别任务的好处,像Kinetics这样的数据集的引入刺激了新网络架构的发展,带来了令人印象深刻的性能提升。然而,正如引言中所描述的,这些数据集的标签成本极其高昂。一些工作尝试通过启发式方法减少这种标签成本,或者通过获取弱标签(例如元数据中的标签)。最近,越来越多的研究兴趣集中在利用视频中可用的音频流进行跨模态监督。这些方法大多集中在非语音音频上,例如“吉他演奏”、篮球的“嘭”声或海浪的“撞击”声,而不是转录的语音。正如引言中所述,转录语音仅在某些特定领域使用,例如讲解视频和生活视频博客。与这些工作相比,我们专注于电影和电视节目领域(其中语音和动作之间的联系不那么明显)。此外,这些方法使用视频中几乎所有的语音来学习更好的整体视觉嵌入,而我们注意到语音通常与动作无关。因此,我们首先从书面材料中学习语音和动作之间的关联,然后将这些知识应用于未标注的视频集合中,以获取可以直接用于训练的视频片段。
3. Speech2Action模型
在本节中,我们描述了从大型剧本数据集中训练Speech2Action分类器所需的数据准备、数据挖掘和学习步骤。然后我们评估了它从转录的语音片段中预测视觉动作的性能。
3.1 IMSDb 数据集
电影剧本是包含舞台指令(例如“Andrew走过去开门”)和角色对话(例如“请进”)的丰富数据源。由于舞台指令通常包含描述的动作,我们利用剧本中对话和舞台指令的共现来学习“动作”和对话之间的关系(见图1)。在这项工作中,我们使用从IMSDb网站提取的剧本集合。为了获得各种不同的动作(例如“推”、“踢”以及“吻”和“拥抱”),我们使用涵盖各种不同类型的剧本。总共我们的数据集包括1,070部电影剧本(见表1的数据集统计)。我们将这个数据集称为IMSDb数据集。
剧本解析
虽然剧本(通常)对其部分有标准化格式(例如,
镜头标题、舞台指令、对话、过渡等),但由于布局和格式的差异,解析它们具有挑战性。我们按照Winer等人提出的基于《好莱坞标准》的语法来解析剧本并分离出剧本的各种元素。该语法将剧本解析为以下四个不同元素:(1)镜头标题,(2)舞台指令(包含动作提及),(3)对话,(4)过渡。在这项工作中,我们只提取(2)舞台指令和(3)对话。我们提取了超过50万条舞台指令和超过50万条对话语句(见表1)。需要注意的是,由于剧本解析是使用自动方法完成的,有时手工输入的剧本遵循完全非标准的格式,因此提取并不完美。对100个随机提取对话进行的快速人工检查表明,大约85%确实是对话,其余的是错误标记为对话的舞台指令。
动词挖掘舞台指令
并非所有动作都与语音相关——例如“坐下”和“站起来”这样的动作很难仅通过语音区分,因为它们在所有类型的语音中都常见。因此,我们的首要任务是自动确定由语音单独“辨别”的动词。为此,我们使用上面描述的IMSDb数据集。我们首先获取数据集中的所有舞台指令,并将每个句子分解为干净的单词标记(没有标点符号)。然后,我们使用NLTK工具包确定每个单词的词性标签,并获得所有动词列表。出现频率少于50次的动词(包括许多拼写错误)或出现频率过高的动词(即最常见的100个动词,如“be”等)被移除。对于每个动词,我们将所有动词的变位和单词形式进行分组,例如动词词干“run”可以有许多不同形式——running、ran、runs等,我们使用UPenn XTag项目手动创建的动词变位列表。所有这些动词类都用于训练基于BERT的语音到动作分类器,下面描述。
基于BERT的语音分类器
然后从属于上述动词类的动词中解析每个舞台指令。我们使用电影剧本中的接近度作为线索,获取配对的语音-动作数据。因此,最接近舞台指令的语音片段(如图1所示)被分配给舞台指令中的每个动词一个标签。这为我们提供了匹配动词标签的语音句子数据集。不出所料,这是一个非常嘈杂的数据集。通常,语音与分配给它的动词类无关,并且相同的语音片段可以分配给许多不同的动词类。为了学习语音和动作之间的关联,我们使用850部电影训练分类器,其余的用于验证。所使用的分类器是一个预训练的BERT模型,带有一个额外的分类层,在与弱“动作”标签配对的语音数据集上进行微调。具体模型细节如下所述。
实现细节
所使用的模型是BERT-Large Cased with Whole-Word Masking (L=24, H=1024, A=16, 总参数=340M) 预训练仅在英文数据上(BooksCorpus(8亿词,Wikipedia 语料库(25亿词)),因为IMSDb数据集仅包含英文电影剧本。我们使用WordPiece嵌入,具有30,000个标记词汇表。每个序列的第一个标记总是一个特殊的分类标记([CLS])。我们使用与第一个输入标记[CLS]对应的最终隐藏向量C ∈ R^H 作为聚合表示。唯一在微调期间引入的新参数是分类层权重W ∈ R^K×H,其中K是类的数量。我们使用标准的交叉熵损失,C和W,i.e., log(softmax(W^T C))。我们使用批量大小为32的批量进行微调,并在IMSDb数据集上进行100,000次迭代,使用Adam求解器,学习率为5 × 10^-5。
结果
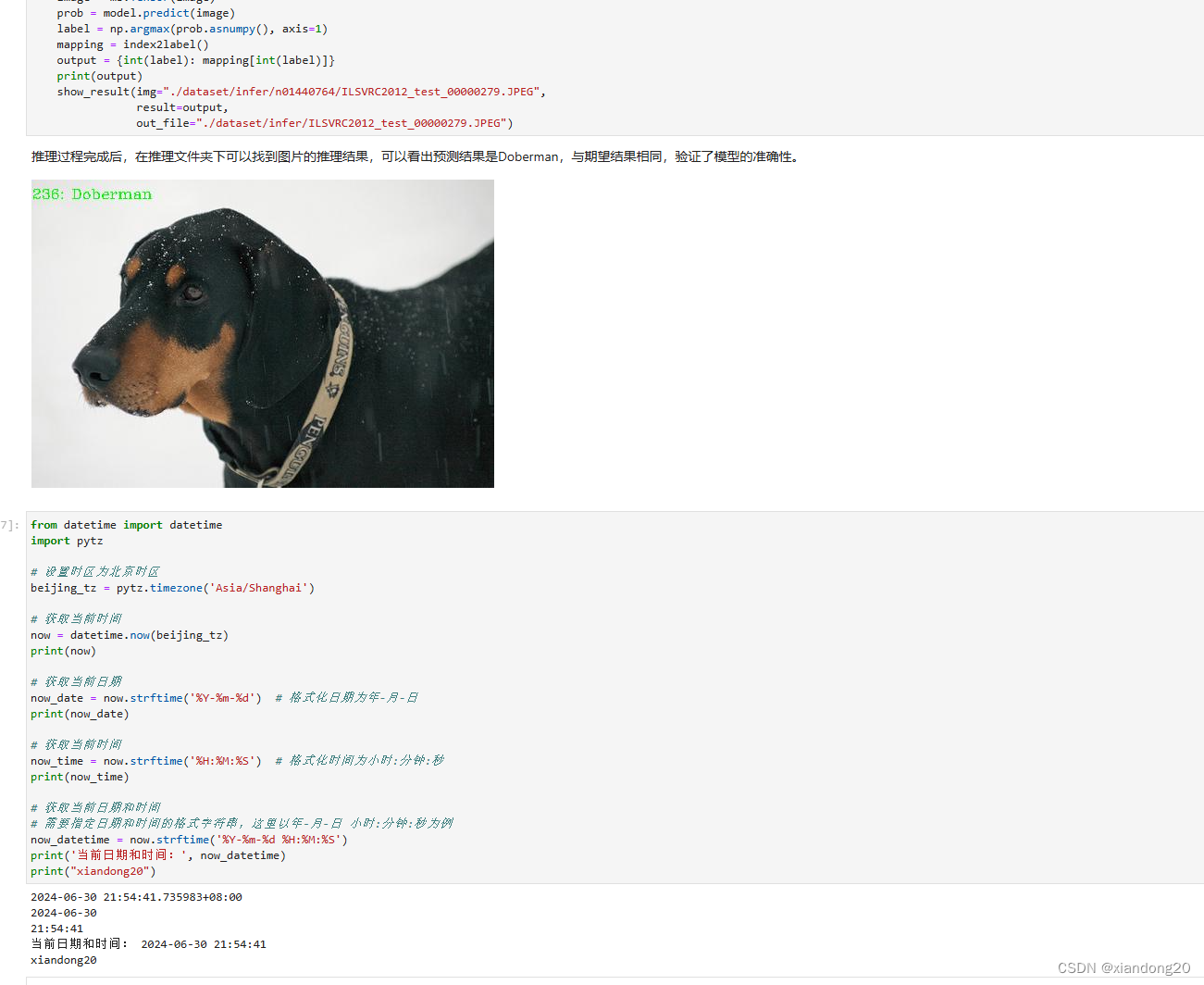
我们在220部电影剧本的验证集上评估了模型的性能。我们使用从Speech2Action模型获得的softmax分数绘制了精度-召回曲线。只有那些平均精度(AP)高于0.01的动词被推断为与语音相关。最高的动词类是“phone”、“open”和“run”,而像“fishing”和“dig”这样的动词类的平均精度很低。我们最终得出结论,有18个动词类与语音有很强的关联。图2展示了6个动词类最自信的预测的定性示例(使用softmax分数作为自信度的衡量标准)。我们注意到,我们使用纯数据驱动的方法从电影剧本中学习了动作动词和语音之间的关联。关键假设是,如果动词在电影剧本中的某个趋势在语音片段前后出现,并且我们的模型能够利用这个趋势来最小化分类目标,我们推断语音与动作动词相关。因为评估完全基于电影剧本中语音与动词类的接近性,它不是一个完美的标注,不能仅通过电影剧本来判断动作是否实际发生在视频中(这是无法判断的)。在这种情况下,我们将舞台指令作为伪标注,即如果舞台指令包含一个动作,然后演员说了一句特定的句子,我们推断这两者必须相关。作为一个合理性检查,我们还手动标注了一些视频,以更好地评估Speech2Action模型的性能。这在第4.2.3节中描述。
4. 动作识别视频挖掘
现在我们已经学习了Speech2Action模型来从转录的语音中映射动作(仅从文本中),在本节中,我们展示了如何将其应用于视频。我们使用该模型从大量未标注的语料库中自动挖掘视频示例,并使用Speech2Action模型预测的弱标签对其进行标注。利用这些弱标签数据,我们直接训练模型进行视觉动作识别任务。挖掘的详细训练和评估协议在以下各节中描述。
4.1 未标注的数据
在这项工作中,我们将Speech2Action模型应用于一个大型内部电影和电视节目的语料库。该语料库包含222,855部电影和电视节目剧集。对于这些视频,我们使用闭幕字幕(请注意,这可以直接从音频轨道中使用自动语音识别获得)。该语料库总共有188,210,008条闭幕字幕,分成句子后总数为390,791,653(几乎4亿句)。虽然我们在这项工作中使用了这个语料库,但我们要强调的是,训练Speech2Action模型所使用的文本数据与这个未标注的语料库之间没有任何关联(除了它们都属于电影领域),这种模型可以应用于任何其他未标注的编辑视频素材。
4.2 获取弱标签
在本节中,我们描述了如何从语音中获得短片的弱动作标签。我们通过两种方式进行,(i)使用Speech2Action模型,(ii)使用简单的关键词定位基线。
4.2.1 使用Speech2Action
Speech2Action模型应用于单个语音句子,如果置信度(softmax分数)高于某个阈值,则预测结果用作弱标签。阈值通过在IMSDb验证集上取精度为0.3的置信值获得,并对“phone”、“run”和“open”类进行了一些手动调整(由于这些类的召回率较高,我们提高了阈值,以防止检索样本的不平衡)。然后我们提取以字幕时间框架中点为中心的10秒视频片段的视觉帧,并将Speech2Action标签作为该片段的弱标签。最终,我们成功挖掘了837,334个视频片段,涵盖了18个动作类。虽然产量低,但我们仍然获得了大量的挖掘片段,超过了手动标注的Kinetics数据集(60万)。我们还发现,在IMSDb数据集中与语音高度相关的动词类在其他数据集中往往是罕见或稀有的动作类——如图3所示,我们在AVA训练集中某些类中获得的数据多达两个数量级。图4展示了具有动作标签的挖掘视频片段的定性示例。注意我们仅通过语音检索到了背景和演员各异的片段。更多展示物体和视点多样性的示例见补充材料图5。
4.2.
2 使用关键词定位基线
为了验证从电影剧本中训练的Speech2Action模型的有效性,我们还与一个简单的关键词定位基线进行比较。此方法涉及直接在语音中搜索动作动词——如语音片段“你现在要吃吗?”直接分配“eat”标签。此方法本身是一个非常强大的基线,例如语音片段“你愿意和我跳舞吗?”强烈指示动作“跳舞”。为了实现此基线,我们直接在语音片段中搜索动作动词(或其变位),如果动词出现在语音中,我们直接将动作标签分配给视频片段。此方法的缺陷在于无法区分动词的不同语义,如语音片段“你完全错过了重点”将被弱标记为“point”,其表示的语义与指向的物理动作不同。因此,我们在结果中展示了此基线与我们Speech2Action挖掘方法相比表现较差。更多使用此关键词定位基线标记的语音示例见补充材料表1。
4.2.3 Speech2Action的手动评估
我们现在评估Speech2Action应用于视频的性能。给定一个语音片段,我们检查模型在语音上的预测是否转换为视觉上动作在与语音对齐的帧中发生。为了评估这一点,我们手动检查100个随机检索的视频片段的10个动词类,并报告真实正例率(动作可见的片段数)。我们发现,在10秒的时间框架内,出人意料地,许多样本确实包含了动作,某些类的噪音较大。类“run”和“phone”的高纯度可以通过使用较高的挖掘阈值来解释,正如第4.2.1节所述。常见的误报源是动作在屏幕外执行,或动作在语音片段前后时间上偏移(要么早得多,要么晚得多)。我们注意到,我们从未实际使用任何手动标签进行训练,这些纯粹是用于评估和合理性检查。
5. 动作分类
现在我们已经描述了如何获取弱标记的训练数据,我们使用S3D-G骨干网络在这些嘈杂的样本上训练视频分类器以进行动作识别任务。我们首先详细介绍训练和测试协议,然后描述本文使用的数据集。
5.1 评估协议
我们通过以下两种方式评估视频分类器在动作分类任务中的表现:
- 首先,我们遵循视频理解文献中采用的典型程序:在用Speech2Action弱标记的一个大型视频语料库上进行预训练,然后在标记的目标数据集的训练集上进行微调。训练完成后,我们评估目标数据集测试集的性能。在本文中,我们使用HMDB-51,并与其他最新方法在该数据集上的表现进行比较。我们还提供了UCF101数据集的结果。
- 其次,也是更有趣的,我们应用我们的方法,通过在一些动作类上使用挖掘的视频片段训练视频分类器,并直接在目标数据集(在本例中我们使用AVA数据集)的稀有动作类的测试样本上进行评估。请注意,在此过程中我们还手动验证了IMSDb数据集和AVA数据集中的电影没有重叠(不奇怪,因为AVA电影较旧且较不知名——这些是YouTube上免费提供的电影)。在这种情况下,未使用单个手动标注的训练示例,因为没有微调(我们因此将其称为零样本)。我们还报告少样本学习情景的性能,我们在少量标记示例上微调我们的模型。我们注意到,在这种情况下,我们只能评估与IMSDb数据集中动词类直接重叠的类。
5.2 数据集和实验细节
HMDB51:HMDB51包含来自51个动作类的6766个现实且多样的视频片段。评估是使用平均分类准确度在三次训练/测试分割中进行的,每次分割有3570个训练视频和1530个测试视频。
AVA:AVA数据集通过详尽手动注释的视频收集,并在常见类和稀有类之间表现出强烈的不平衡。例如,一个常见的动作,如“站立”,有160K训练和43K测试示例,相比之下,“驾驶”有1.18K训练和561测试示例,“指向”只有96训练和32测试示例。因此,依赖于完全监督的方法在中尾类上表现较差。我们评估了AVA数据集中与IMDSDb数据集中的类重叠的14个类(均来自中尾类)。虽然该数据集最初是一个检测数据集,我们将其重新用于动作分类任务,通过将每帧分配所有边界框注释的联合标签进行训练和测试。我们在这些14个动作类的样本上进行训练和测试,并报告每类的平均精度(AP)。
实现细节
我们使用S3D-G作为我们的视觉分类器。遵循前人的方法,我们从一个视频中密集采样64帧,将输入帧大小调整为256×256,然后在训练期间进行224×224的随机裁剪。在评估期间,我们使用所有帧并从调整大小的帧中进行224×224的中心裁剪。我们的模型用TensorFlow实现,并用带有动量0.9的标准同步SGD算法优化。对于从头训练的模型,我们进行150K次迭代训练,学习率调度为10-2、10-3和10-4,分别在80K和100K次迭代后下降,对于微调我们进行60K次迭代训练,学习率为10-2。
训练的损失函数
我们尝试了softmax交叉熵和每类sigmoid损失,发现两者的性能相对稳定。
5.3 结果
HMDB51:在HMDB51上的结果见表3。用Speech2Action标记的视频进行预训练显著提高了17%的性能。作为参考,我们还与其他自监督和弱监督工作进行比较(请注意,这些方法在架构和训练目标上有所不同)。我们展示了14%的改进,超过了以前仅使用视频帧(没有其他模态)的自监督工作。我们还与Korbar等人进行比较,他们在AudioSet上使用音频和视频同步进行预训练,DisInit通过将ImageNet知识转移到Kinetics视频,简单地在ImageNet上进行预训练然后将2D卷积扩展到我们的S3D-G模型。我们比这些工作提高了3-4%,这是令人印象深刻的,因为后两种方法依赖于大规模手动标注的图像数据集,而我们的工作仅依赖于1000个未标注的电影剧本。另一个有趣的点(也许是这种自监督和弱监督研究的不可避免的副产品)是,虽然所有这些以前的方法都没有使用标签,但它们仍然在经过精心策划的Kinetics数据上进行预训练,该数据涵盖了600多种不同的动作。相比之下,我们直接从电影中挖掘训练数据,而无需任何手动标注或精心策划,我们的预训练数据仅挖掘了18个类。
AVA-scratch
在AVA上从头训练的模型的结果见表4(前4行)。我们比较了以下几种方法:使用AVA训练示例训练,只用我们挖掘的示例训练,和联合训练。对于14个类中的8个类,在没有任何AVA训练示例的情况下,我们超过了完全监督的性能,在某些情况下(例如“驾驶”和“电话”)几乎提高了20%。
AVA-finetuned
我们还展示了首先在Speech2Action挖掘的片段上进行预训练,然后在逐渐增加的每类AVA标记训练样本上进行微调的结果(表4,后4行)。在每类50个训练样本的情况下,我们在除“拥抱”和“推”外的所有类上超过了从头训练的完全监督性能。类“拥抱”的最差表现——“拥抱”和“吻”常常混淆,因为两者的语音通常相似——“我爱你”。快速人工检查表明,大多数片段被错误标记为“吻”,这就是为什么我们仅能挖掘到非常少的“拥抱”视频片段。为了完整性,我们还在Speech2Action挖掘的片段上预训练模型(仅14个类),然后在AVA上进行所有60个类的微调,并获得40%的总体分类精度,而仅在AVA上训练获得38%。
挖掘技术
我们还使用关键词定位基线挖掘的片段进行训练(表4)。对于某些类,此基线本身超过了完全监督的性能。我们的Speech2Action标记在所有类上超过了此基线
,特别是“point”和“open”类——这些动词有许多语义,这证明了从IMSDb数据集中学习的语义信息是有价值的。然而,我们注意到,由于AVA测试集中存在的个别问题(少数测试样本的标注错误),很难量化评估类“point”的性能,因此我们展示了一些挖掘的片段的定性示例。我们注意到,对于“跳舞”和“吃”的类,基线非常接近,表明简单的语音关键词匹配可以为这些动作检索到好的训练数据。
抽象动作
通过直接从电影剧本中的舞台指令收集数据,我们的动作标签是后定义的(如前人的方法)。这与大多数现有的人类动作数据集使用预定义标签不同。因此,我们还设法挖掘了一些与语音高度相关的非标准或抽象动作示例,如“计数”和“跟随”。虽然这些动作不在标准动作识别数据集(如HMDB51或AVA)中,无法进行量化评估,但我们展示了一些这些挖掘视频的定性示例。
6. 结论
我们提供了一种新的数据驱动方法,通过仅使用语音来获取动作识别的弱标签。仅使用一千个未对齐的剧本作为起点,我们自动为多个稀有动作类获得弱标签。然而,网上有大量的文学材料,包括戏剧和书籍,利用这些文本资源可能允许我们扩展我们的方法以预测其他动作类,包括“动词”和“物体”的复合动作。我们还注意到,除了动作,人们谈论物理物体、事件和场景——这些描述也存在于剧本和书籍中。因此,本文使用的原理可以应用于为更一般的视觉内容挖掘视频。